[ウルドゥー語/ヒンディー語 語彙検索]
一般ヘルプ
ウルドゥー語/ヒンディー語 語彙検索CGIの一般ヘルプです。
ウルドゥー語スペル入力のためのヘルプは、ウルドゥー語スペル入力ヘルプを見てください。
- 機能と表示
- 以下の3通りの検索ができます。
- 発音をローマ字で入力して検索します(先頭一致)。
- スペルに即した検索をします(先頭一致)。具体的には……
- [URDUスペル……ウルドゥー語版]ウルドゥー語のスペルをそのままローマ字転写して検索します。詳しくはURDU入力ヘルプ
- [無点スペル……ヒンディー語版]
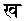 と
と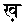 など、点の有無を無視して検索します。
など、点の有無を無視して検索します。
- 訳文を日本語で検索します(任意箇所一致)。簡易和印辞典として使えます。
2つ以上の入力窓に入力した場合は、
AND検索(複数の条件をすべて満たすものの検索)になります。
もっとも、発音とスペルを同時に入力しても、
現実にはあまり意味はないと思います。
「訳文」欄は、スペースで区切って複数の語を入力することができます。
その場合は、その単語すべてを含むものを検索します。
- 表示は、ウルドゥー語版では発音−ウルドゥー語スペル−ヒンディー語スペル、
ヒンディー語版では発音−ヒンディー語スペル−ウルドゥー語スペルです。
両者の発音が異なる場合は、
(HINDI=xxxx)(URDU=xxxx)のような形で、発音を表示しています。
ウルドゥー語でしか用いられない単語はウルドゥー語のスペルのみ、
ヒンディー語でしか用いられない単語はヒンディー語のスペルのみを表示しています。
- アラビア語起源の語については、1行目の表示の最後に、(A辞書×××)という形で、
その語がアラビア語の辞書でどの位置に載っているかを示しています。
たいていのアラビア語辞書は語そのものの字母順ではなく、
語根の字母順に載っているため、
アラビア語の文法に詳しくないと非常に引きにくいためです。
なお、×××の部分のアラビア文字は画像ではなくUnicodeで表示しているので、
環境によっては正しく表示されません。
一応アラビア語の定番辞書
Wehr & Cowan : Arabic-English Dictionaryで確認していますが、
「同辞書に収録されていないが理論的にはここに入るはず」というのも載せているので、
必ずしもこの辞書で見つかるとは限りません。
また、アラビア語起源とはいっても、
「場所的にはこの位置だが実際にはそういう語は存在しない」
「アラビア語では定冠詞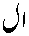 がつく」
「語末の
がつく」
「語末の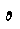 や
や が、
アラビア語では
が、
アラビア語では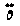 になっている」
「同じ語なのにアラビア語では意味が違う」
などいろいろ違うことがありますので注意が必要です。
になっている」
「同じ語なのにアラビア語では意味が違う」
などいろいろ違うことがありますので注意が必要です。
- 「A辞書」について、ハムザはすべてアレフにまとめました(辞書ではその位置にあるからです)。
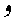 や
や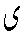 とセットになっているものも含めてすべてアレフ
とセットになっているものも含めてすべてアレフ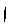 と表記しているので注意してください。
と表記しているので注意してください。
- 2行目に、品詞、由来(固有語か外来語か)、訳文を表示しています。
訳文内でのウルドゥー語/ヒンディー語は、
一部原文字どおりのスペルを書いている場合がありますが、
基本的にはローマ字転写のみで示します。
- その語に関連した文法トピックスがある場合は、3行目以降に表示しています。
- この語彙集のデータはまんどぅーか友の会会員(→入会案内)専用で無償配付しています。
必要な方は会員専用ページからダウンロードしてください。
- 単語入力のしかた
- 当サイトで採用しているローマ字転写法に準拠します。
具体的には文字と発音を見てください。
特殊記号のついた文字は次のように入力します。
なお、大文字と小文字の区別をしていないので、
すべて小文字で入力すればOKですし、
携帯電話の中には小文字の入力の面倒な機種もあるようなので、
そういう場合は気にせずすべて大文字で入力していただいても結構です
(この処理により思わぬ語がヒットしてしまうことがあるのでご容赦ください)。
- 母音について
- 長母音
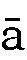 、
、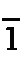 、
、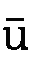 はaa、ii、uuのように入力します。
はaa、ii、uuのように入力します。
 、
、 は長母音ですが記号がついていないのでそのままです。
短母音である
は長母音ですが記号がついていないのでそのままです。
短母音である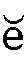 、
、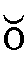 も、入力の際にはe、oと入力します。
も、入力の際にはe、oと入力します。- 鼻母音はnをつけます。
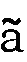 はan、
はan、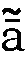 はaanです。
つまり、
はaanです。
つまり、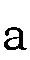
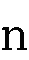 、と区別なく入力します。
、と区別なく入力します。
- ヒンディー語の
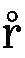 は、rと入力します。
は、rと入力します。
- 子音について
- 下に点のついた、
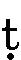 、
、 、
、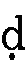 、
、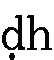 、
、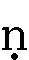 、
、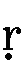 、
、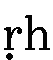 、
、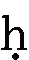 は、
点のない文字同様に、t、th、d、dh、n、r、rh、hと入力します。
は、
点のない文字同様に、t、th、d、dh、n、r、rh、hと入力します。
- 同様に、上にナナメや谷形や波形のついた、
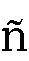 、
、 、
、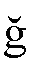 、
、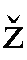 は、
n、s、g、zと入力します。
は、
n、s、g、zと入力します。
- ただしヒンディー語の
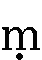 (アヌスヴァーラ、ピンドゥ)は、mでなくnと入力してください。
(アヌスヴァーラ、ピンドゥ)は、mでなくnと入力してください。
- このように、別の子音を同一の文字として検索しているので、思わぬ語がヒットしてしまうことがあります。ご容赦ください
- その他について
- 空白は_と表示しますが、入力の際には入れる必要はありません。
- na'iiなどの'は、表示はしますが、入力の際には入れる必要はありません。
- -は、表示はしますが、入力の際には入れる必要はありません。
- 検索のコツ
- ウルドゥー語
ウルドゥー語の発音は、特に短母音に関していろいろなゆれがあるので、発音検索ではうまく検索できない場合があります。スペルがわかっている場合は、「URDUスペル」による検索をお勧めします。「URDUスペル」の入力のしかたは、URDU入力ヘルプを見てください。
スペルに関して一点ゆれていることとして、末尾がと発音されるで終わる語の問題があります。これらはと発音されるため、けっこうで表記されることも多く、辞書にはどちらのスペルも記されています。この語彙集ではどちらか一方しか収録されていないので、このような語は末尾の(URDU入力ではo)や(URDU入力ではa)を除いて検索することをお勧めします。
- ヒンディー語
ヒンディー語ではスペルと発音とがほぼきれいに対応していますが、次のような問題があります。
- 短母音aを発音するかどうかがゆれている語がある
- 子音+子音を結合子音字で表すかどうかがゆれている語がある
- 鼻子音+子音を結合子音字で表すかアヌスヴァーラ+子音で表すかがゆれている語がある
- 複合語の各要素をくっつけるかハイフンでつなぐかスペースをあけるかがゆれている語がある
といった問題があり、うまく検索できない場合があります。
この問題に対応するため、
ヒンディー語版CGIの「発音」「無点スペル」による検索では次のような工夫をしています。
- 短母音aの有無は、単語冒頭を除いて一切無視しています。
- 子音+子音は、結合子音字を用いるかどうかを無視しています。
- 鼻子音、チャンドラピンドゥ、ピンドゥはすべて同一のものとしています。
- ハイフンやスペースは切り詰めて検索しています。
ユーザーの入力する文字も同様の処理をしているので、
ユーザーは上記のことを考慮する必要はありません
(ただし、をmでなくnと入力することだけ注意してください)。
が、上記の処理により思わぬ語がヒットしてしまうことがあるのでご容赦ください。
- ヒンディー語無点スペル検索
ヒンディー語の無点スペル検索は、ほとんどの点でヒンディー語発音検索と同じで、さらに次の文字を同一視して検索します。
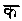 (
(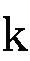 )と
)と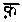 (
(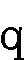 )
)- (
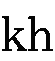 )と(
)と(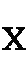 )
)
 (
( )と
)と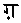 ()
()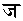 (
(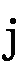 )と
)と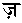 (
(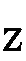 )
)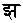 (
( )と
)と ()
()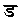 ()と
()と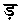 (
(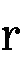 )
)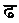 ()と
()と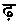 (
(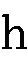 )
) (
( )と
)と (
(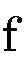 )
)
- 略号
- 品詞略号は以下のとおりです。
男)男性名詞、女)女性名詞、形)形容詞、
代)代名詞、副)副詞、自)自動詞、他)他動詞、助)助動詞、
接)接続詞、間)間投詞、後)後置詞。
- 由来(語が固有語であるか外来語であるか)の略号は以下のとおりです。
H)ヒンディー語(固有語)、P)ペルシア語、A)アラビア語、
T)トルコ語、C)中国語、Po)ポルトガル語、E)英語。
- CGIの起動方法
- このCGIのURLは、
- ウルドゥー語版がhttp://www.manduuka.net/urdu/w/udic.cgi、
- ヒンディー語版がhttp://www.manduuka.net/urdu/w/udich.cgi
です。
http://www.manduuka.net/urdu/w/ と省略した場合は、ウルドゥー語版(udic.cgi)が起動します。
次で述べるパラメータを指定するときは、udic.cgiを省略してはいけません。
- これらのURLのあとに?をつけて、パラメータを指定することができます。
- word= ……発音欄
- urdu= ……URDUスペル欄(ウルドゥー語版のみ)
- text= ……訳文欄
- imode= …… 1で強制的にi-mode用。0で強制的にPC用
- num= …… 1ページに表示する語数。デフォルトはi-mode用が1、PC用は5。最大数は特に制限ナシ。ただしi-mode用で大きな数字を指定するとページが大きすぎて表示不能になる場合あり。
(例) http://www.manduuka.net/urdu/w/udic.cgi?urdu=emr
複数のパラメータは & で連続して指定します。
textを複数個指定するときは、 text=xxx&text=yyy のようにします。
また、OSやブラウザによっては日本語のエンコードがうまくいかないので、
textを指定しても思い通りの検索ができないことがあります。
- 頼っている資料
- この語彙集は当初は「文法超特急」の「ウルドゥー語入門」に出てきた単語にいくばくかのプラスアルファをしたものでしたが、その後いろいろな基礎語彙集に頼って語彙を増強してきました。その中でも主に頼ってきた資料は、
です。
- ウルドゥー語の語彙をヒンディー語でも同じように言うのかどうか、そしてヒンディー語の標準的なスペルのチェック用に、Oxford Hindi-English Dictionaryを用いています。
もっともこの辞書はウルドゥー語語彙とされる語彙をかなり寛容に入れている方です。
この辞書に載っているものはヒンディー語中心語彙検索にも登録しています。
当ヒンディー語語彙検索で「ウルドゥー語語彙」と表示されているものは主にそれにあたります。
また時折、土井久弥編『ヒンディー語小辞典』をも見ています。
- 逆に、ヒンディー語の辞書にある単語を、ウルドゥー語でもそう言うかどうかは、
(『ウルドゥー語常用6000語』ではさすがに語数不足なので)
Standard 20th Century Dictionary, Urdu into Englishを用いています。こちらの辞書にも若干のヒンディー語語彙が、dial.(方言)、rare.(まれ)というような表記をつけて収録されています。当ウルドゥー語語彙検索で「ヒンディー語語彙」と表示されているものは主にそれにあたります。
