
Since 2005/9/24 Last Updated 2005/9/27
|
ウルドゥー語のソートに引き続き、ヒンディー語のソートの方法を考える。 当サイトでのヒンディー語の内部表現コードは「まんどぅーかネットで使っている技術(4)」で明らかにしているので、ここに引用するのは割愛する。必要に応じてこのページを参照してほしい。 このコードはソートを意識した順序になっているが、やはりこのコードそのままでは辞書順ソートにはならない。どんなにうまいコードを定めても辞書順ソートはムリなのである。そのことはウルドゥー語のソートに書いてあるのでもう繰り返さない。まだ読んでいない人は読んでほしい。辞書順ソートのためにはこのコードをさらにもう一歩加工しなければならないのである。 ヒンディー語のソートで主に問題になる点ごとに話を進めていこう。 ヒンディー語には鼻母音を表すチャンドラピンドゥ( 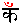 の赤字部分)や、鼻子音を表すピンドゥ( の赤字部分)や、鼻子音を表すピンドゥ( の赤字部分)のような記号がある。普通、このような記号のついた文字は辞書順ソートではいったん無視し、後に記号のない文字のあとに並べるものであるが、ヒンディー語ではまったく違う。記号がついたほうが先になるのである。しかも、あたかも記号のない文字とはまったく別の文字として、記号のない文字よりも完全に先にするのである。 の赤字部分)のような記号がある。普通、このような記号のついた文字は辞書順ソートではいったん無視し、後に記号のない文字のあとに並べるものであるが、ヒンディー語ではまったく違う。記号がついたほうが先になるのである。しかも、あたかも記号のない文字とはまったく別の文字として、記号のない文字よりも完全に先にするのである。もっともこれは、辞書順ソートの面倒くさい手順をふまなくていいということを意味する。記号のついた文字に対して記号のない文字より若いコードを割り当てておけば、そのコードの順にソートするだけでいいのである。だからこのこと自体は全然難しくない。 逆に、ローマ字などから内部表現コードに直す際に、母音が鼻母音になるかどうか、次に鼻子音が来るかどうかを先読みしなければならない。たとえば さて、当サイトの内部表現コードでは、鼻母音は普通の母音よりも1だけ若いコードをわりあてている。だから鼻母音に関しては正しくソートできる。しかし鼻子音 なお、「鼻母音と鼻子音をまったく同じにしてしまっていいのか? 辞書順ソートの要領で、同じにするならどっちかに重みをつけねばならないのではないか」という問題があるが、「鼻母音と鼻子音だけの違いであとはまったく同じ」という語はめったにない。McGregorの辞書(Oxford Hindi-English Dictionary)をぱらぱらとめくると、 なお、ヒンディー語ではこれでいいのであるが、他の言語では鼻母音の扱いが異なる。たとえばサンスクリットでは違う処理をしなければならない。その話はサンスクリットのソートのところで述べることとする。 ヒンディー語にもごくまれにヴィサルガ(  の赤字部分)が出てくる。いかにも記号っぽい文字であるが、ヒンディー語では一個の独立した文字として扱い、母音字のあと、子音字の前に並べる。内部表現コードでは24をわりあてているが、これは母音字の最後 の赤字部分)が出てくる。いかにも記号っぽい文字であるが、ヒンディー語では一個の独立した文字として扱い、母音字のあと、子音字の前に並べる。内部表現コードでは24をわりあてているが、これは母音字の最後これもサンスクリットではやっかいな問題が出てくるのだが、その話はやはりサンスクリットのソートのところで述べることとする。 デーヴァナーガリーの子音字には、特別な記号がつなかい限りすべて潜在母音 内部表現では なお、デーヴァナーガリーの母音字には独立体と記号の2つがあるので、コードも別にしなければいけないような気がするが、これは同じにしてかまわない。ただしこの潜在母音 結合子音字はすべての母音の後に来る。たとえば 後にまわすためには特別なコードを出力しなければならないような気がするかもしれないが、その必要はない。子音のコードは母音よりも大きいのだから、何もしないで大丈夫である。たとえば もちろん結合子音とそうでない場合とをローマ字転写の段階でしっかり区別しておかないと、 もっとも、語の末尾がヴィラーマで終わる場合がごくまれにある。当サイトの語彙集に登録されているものでは、  、 、 、 、 の3語である。このうちに関しては、ヴィラーマなしの語もある(当サイトの語彙集には登録していない)ので、順序が問題になるだろう。McGregorの辞書ではヴィラーマなしのものよりも後に配列してある。このためには、「ヴィラーマを見たら重みをつける」処理が必要になるが、問題を起こすのはせいぜいこの語くらいなものなので、「何もしない」というのも賢明なやり方だと思う。 の3語である。このうちに関しては、ヴィラーマなしの語もある(当サイトの語彙集には登録していない)ので、順序が問題になるだろう。McGregorの辞書ではヴィラーマなしのものよりも後に配列してある。このためには、「ヴィラーマを見たら重みをつける」処理が必要になるが、問題を起こすのはせいぜいこの語くらいなものなので、「何もしない」というのも賢明なやり方だと思う。なお、結合子音字を使うか使わないかがゆれている語というのはけっこうあるが、このソートでは、結合子音にするかしないかではずいぶん位置が異なってしまう。しかしそれはヒンディー語の辞書の一般的な流儀なのでいたし方あるまい。 ヒンディー語では点のついた子音字がいくつかある。具体的には 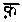
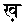
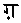
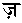

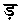
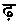
 の8字である。これらは点のない文字と同じものとして処理し、それによって同じ文字列ができてしまったときには、点のない文字列よりも後にする。要は「辞書順ソート」の要領である。当サイトではウルドゥー語のソートのところで述べた「手抜き重み」つまり、単に文字列の先頭からの位置と同じ数値を重みとして加算している。
の8字である。これらは点のない文字と同じものとして処理し、それによって同じ文字列ができてしまったときには、点のない文字列よりも後にする。要は「辞書順ソート」の要領である。当サイトではウルドゥー語のソートのところで述べた「手抜き重み」つまり、単に文字列の先頭からの位置と同じ数値を重みとして加算している。
ヒンディー語では複合語がかなり多い。これらは主に「そのままくっつける」「スペースを入れる」「ハイフンでつなぐ」の3種類がある。辞書順ソートの際にはこれらはすべて同じものとみなし、必要に応じて重みで区別する(しなくてもかまわない)ようにする。 なお、辞書によっては、複合語の第一要素のあとに、それを用いる複合語をすべて並べるやり方があるが、それをやりたいのであれば、各成分のあとに00を出力するようにすればよい。そうすればすぐ後に来てくれる。ただし、複合語の第一要素と第二要素の間に音変化がおこってくっついてしまったときにうまくないので、ローマナイズの段階で工夫しておかねばならない。当サイトではこういうことをいっさいやっていないので、この工夫については割愛する。 以上がヒンディー語のソートである。サンスクリットのソートについては少々やっかいな問題があるので稿を改めて記す。 |
※ご意見、ご教示などは、 に戻り、掲示板あるいはメールで賜るとありがたく思います。
に戻り、掲示板あるいはメールで賜るとありがたく思います。