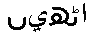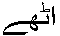Since 2004/9/17 Last Updated 2006/5/30
|
|
ペルシア文字とはウルドゥー語を表す文字のことである。アラビア文字と呼んでもいいのだが、わざわざ「ペルシア文字」と表す場合、よくウルドゥー語で用いられているナスターリーク体のことをさすことが多い。ただ、このページでは必ずしもナスターリーク体のことだけでなく、広くアラビア文字を指している。 このサイトではデーヴァナーガリーもペルシア文字もローマ字も、原則としてすべて画像表示で行くということは再三書いた。ローマ字は活字方式で表示できるから、どんなに語数が多くなろうと音素分の画像ファイルがあればすむが、デーヴァナーガリーやペルシア文字は語ごとに画像ファイルを用意しなければならない。6000語の語彙集を作るなら、単純計算で6000個×2=12000個のファイルが必要になるというわけである。これはかなりしんどいのだが、以下述べるような問題点があるので、当サイトの語彙集では1万数千個のファイルを用意して、オール画像表示を貫いている。 問題点とは何か。「文法超特急」の「ウルドゥー語入門練習問題」では、新出語彙の語彙集を作っている。ここも画像表示にしているが、実はこっそり、Unicodeを指定したページも作ってみた(1番目のみ)。ではそれを見比べてほしい。 みなさんの環境では「Unicode混在版」が正しく表示できているだろうか。完全に正しく表示されているという人は一人もいまい。何らかの問題点が発生していることだろう。Windows 95/98/Meで問題が発生するのは当然なのでXPに話をしぼっても、ブラウザによって表示がまちまちなのだ。複数のブラウザをインストールしている人は、見比べてみると面白いだろう。 複数のブラウザをインストールする気のない人のために、どう見えるかを画像で表示してあげよう。以下は、
NetScapeとMozillaは、出身が同じせいなのか、 ふるまいが同じである。 それではというので、帯気音用 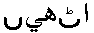 、 、
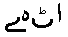 となった。
こんどは
となった。
こんどは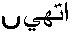 、 、
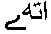 のようにつながるので、やっぱりこれは
のようにつながるので、やっぱりこれは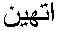 、 、
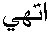 のようにきれいにつながってくれるけど、
これはもうウルドゥー語と言えないよ!
のようにきれいにつながってくれるけど、
これはもうウルドゥー語と言えないよ!一番優秀だったのがOperaだけど、 よく見ると帯気音用の また、 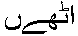 となってしまう。
1746はあくまで語末だけというわけだ。
とすると、コードを使う側が、語末かどうかを判断して、
コードを出し分けてやらねばならないというわけだ。
こういうのは本来はコンピュータさんにやってもらいたいんだけどね。
となってしまう。
1746はあくまで語末だけというわけだ。
とすると、コードを使う側が、語末かどうかを判断して、
コードを出し分けてやらねばならないというわけだ。
こういうのは本来はコンピュータさんにやってもらいたいんだけどね。それやこれやで、目下のところ、WindowsXP上のブラウザの表示にはどれも不満点があった。 これでは当分は、画像切り取りをしなければなるまい。 仮に表示がいまよりましになったところで、上に書いたように、 使う側が語頭・語中・語末を判断してコードを出し分けねばならないケースも残りそうだし、 もうわずらわしくて書かなかったが、現在はどのブラウザも、 ハムザの組み立てにうまく対応していない。 つまり、ハムザ+などのようなハムザのついた文字は別にコードがあるのだが、 ハムザのコードとのコードを送れば勝手に組み立ててくれるというわけではなく、 組みあがった形のコードを送らねばならない。 このようなわずらわしい問題がいろいろ残りそうである。 また、デーヴァナーガリーは、Unicode順にソートすると、 それなりに辞書順になってくれたが(細かい点が違う)、 ペルシア文字はもとのアラビア文字にない拡張した文字のコードがまるきり別のところになっているので、 明らかに辞書順にならない。 仮にUnicodeを送ればブラウザが完璧に表示してくれるようになったとしても、 手元のデータ処理ではUnicode以外のコードを定めて処理しなければならないという状況が続くことだろう。 関連サイト |
※ご意見、ご教示などは、 に戻り、掲示板あるいはメールで賜るとありがたく思います。
に戻り、掲示板あるいはメールで賜るとありがたく思います。